Running Jobs
This section describes how Jobs are organized, run, and managed in Combine. This includes a description of a typical Record Group page within an Organization and the options a user will find there. This page also covers required and optional steps that apply to all the Job types described in parts 9-11.
We also cover “versioning” and “pipelines” here, but these those sections may make more sense after you’ve reviewed Parts 9-11, which describe the various Job types, and after you’ve run some of those Jobs yourself.
Record Versioning
First, an important point about Jobs in Combine. In order to preserve each stage of a Record through harvest, transformation(s), merging, and sub-dividing, Combine copies the Record each time.
As outlined in the Data Model, Records are represented in both MongoDB and ElasticSearch. Each time a Job is run, and a Record is duplicated, it gets a new document in Mongo, with the full XML of the Record duplicated. Copies of a record are associated with each other across Jobs by their Combine ID.
This approach has pros and cons:
- Pros
- simple data model, each version of a Record is stored separately
- each Record stage can be indexed and analyzed separately
- Jobs containing Records can be deleted without affecting copies that are up/downstream (they will vanish from the lineage)
- Cons
- duplication of data is potentially unnecessary if Record information has not changed
- more space needed to store duplicate Records
The Record Group Page
Each Job generates its own pages of results and other data, but the Record Group page allows the user to manage the various Jobs within each Record Group, and keep them organized. As you run more Jobs, you will become increasingly familiar with this page and with the options it provides. After you run a Job, Combine will return you to the Record Group page to which the Job belongs.
At the top of the Record Group page is a graph displaying that Job’s “lineage,” followed by a table displaying all the Jobs within that Record Group:
 |
| A Job “lineage” and a table of Jobs on a Record Group page |
The lineage graph shows how the Jobs in the Record Group are related to one another. The text between nodes show how many Records were used as “input” for a “target Job” (see the section on “Pipelines” below), and which filters, if any, were applied. This graph is zoomable and clickable. It’s intended to provide insight and context at a glance.
The Jobs table is more functional. It shows all of the Jobs in the Record Group and includes a search box at the upper right. The table’s columns are:
- Job ID - a numerical ID that increments with every Job in your instance of Combine
- Last Updated - A timestamp from when the Job began
- Name - An editable field for naming or renaming the Job. It also acts as a link for that Job’s details page (see Part 12: Job Results and Record Details).
- Record Group - The name of the current Record Group. This is also a link to the Record Group that a particular Job falls under. In most cases this will be the same Record Group, but it’s possible for a Record Group to display a Job from another Record Group and advanced users may have good reasons to organize Jobs that way.
- Organization - a link to the Organization this Job falls under
- Job Type - Harvest, Transform, or Merge (see Parts 8-10)
- Status - the status of the Job. The are several possible values here:
- finished - the Job is complete and available
- running - the Job is in process
- waiting - the Job is queued behind other Jobs
- running - The Job is currently running in Livy
- gone - Livy has restarted or stopped, so no information is available
- Is Valid - true/false. False indicates that a Record (or many Records) failed at least one of the Validation Scenarios applied to the Job. True indicates that all Records passed all Validations, though it’s also the result when no Validations were applied to the Job at all
- Publishing - publishing or unpublishing a Job will add or remove it from Combine’s own OAI feed. See “Part 13: Publishing Records” for more.
- Elapsed - how long the Job has been running, or how long the Job took to complete.
- Input - all of the Jobs that provided Records for that Job. This will show “None” if the Job is not “downstream” of another Job (see the section on “Pipelines” below).
- Notes - an optional field for any notes the user wants to add. The Job’s details page will also have a notes field if the user prefers to put them there.
- Total Record Count - the total number of successfully processed Records. A result of ‘0’ here is usually the first sign that a Job setting was incorrect.
- Actions - this cell offers a link to a Job’s details page and also a link to allow the Job to be monitored in Spark (see “Part 2: Installation and Server Maintenance” for more.)
Below the Jobs table is a section for “Jobs Management”:
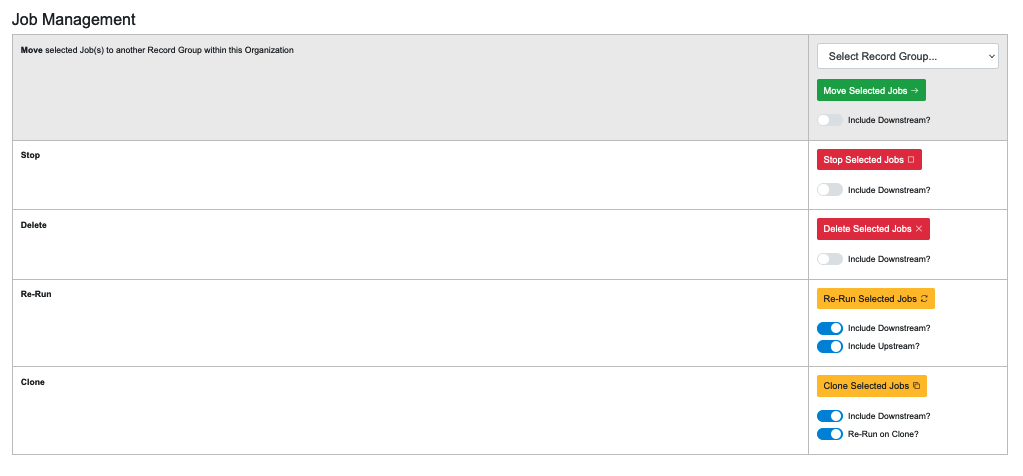 |
| Commands available in the Jobs Management section |
This tab should not be confused with the “Manage” tab on every Job Results page. While the two are very similar, the Job Management section on a Record Group page allows the user to work with several Jobs at once. (For more on the Job Results page, see “Part 12: Job Results and Record Details.”) The commands in this section include:
- Move Selected Jobs: Move them into a different Record Group
- Stop Selected Jobs: In most cases the “Include Downstream” option should be “Yes”
- Delete Selected Jobs: In most cases the “Include Downstream” option should be “Yes”
- Re-Run Selected Jobs: This will re-run any selectedJobs, eliminating the data created when they were previously run. the user can also include Jobs “upstream” and “downstream” of this Job.
- Clone Selected Jobs: Rather than re-run the exact same Jobs, this will create Clones (i.e. duplicates) with the same parameters and run them instead.
All of these options include a slider titled “Include Downstream?” that defaults to on or off, depending on the command. When the slider is on for a particular task, it will analyze the lineage of the selected Jobs and determine which are downstream and include them in the action being peformed (e.g. moving, deleting, etc.) However, it’s important to note that when a Job is re-run, all Jobs that are ‘downstream” of it will also be automatically re-run because, by definition, they have inherited Jobs from the Job in question. (They are “farther down the pipeline.”) See below for a more detailed discussion of pipelines, upstream and downstream.
When it comes to “re-running” and “cloning,” different users may have reasons for preferring one over the other, but it’s important to give some thought to the implications of using each one. The principle behind Combine overall has been to preserve the data of each Job at every step, allowing a User to undo a step if it’s had unintended consequences. The option to “re-run” a Job is an exception to this rule. It will keep the current parameters, applied scenarios, and linkages to other Jobs, but Record data, Mapped Fields, and Validations from the previous run will be dropped (see below for a more in-depth explanation of re-running Jobs). This can make re-running a Job a convenient way to save server space, especially when running large Jobs on a system with limited resources. But if something goes wrong with the “re-run” and if the problem will take time to correct, the user will have a lost any older (but still valid) copies of that Job in the meantime. “Cloning” a Job will ensure that any previous runs of that Job remain intact until the current Job can be confirmed as Valid and reliable. For this reason, users who go with “cloning” may someday be very glad they did. But they should also be mindful about how much server space their multiple clones may be using, and they should get into the habit of weeding older clones regularly.
Selecting a Job Type
Note: For all Jobs in Combine, confirm that an active Livy session is up and running before proceeding.
All Jobs are tied to, and start from, a Record Group. (See “Part 5: The Data Model” for more on Record Groups.) Scroll down on any Record Group page and you will find several buttons for starting new jobs:
 |
| Buttons to start a new Job |
Clicking any of these buttons will initiate a new Job, and present you with the options explained below.
Optional Parameters
Each Job type has its own configuration page, but all of them share a tabbed section of optional parameters that looks like one of the following:
 |
| Optional parameters for Harvest Jobs |
 |
| Optional parameters for Transform and Merge/Duplicate Jobs |
For most of these optional parameters, a user will need to configure each of them ahead of time in the Configurations Page (see “Part 6: Configuration” for a description of this page). Then select which of them to apply to that particular Job.
- Record Input Filter
- Validation Tests
- Transform Identifier
Record Input Filter
When running a new Transform or Duplicate/Merge Job, which both rely on other Jobs as Input Jobs, filters can be applied to incoming Records. These filters can be set on the “Record Input Filter” tab.
There are two ways in which filters can be applied:
- “Globally”, where all filters are applied to all Jobs
- “Job Specific”, where a set of filters can be applied to individual Jobs, overriding any “Global” filters
Setting filters for individual Jobs is performed by clicking the filter icon next to a Job’s checklist in the Input Job selection table:
 |
| Click the Filter Button to set Filters for a specific Job |
This will bring up a modal window where filters can be set for that Job, and that Job only. When the modal window is saved, and filters applied to that Job, the filter icon will turn orange indicating that Job has unique filters applied:
 |
| Orange Filter buttons indicate Filters selected for a specific Job |
When filters are applied to specific Jobs, this will be reflected in the Job lineage graph:
 |
| Job lineage showing specific filters applied to a Job |
and the Input Jobs tab for the Job as well:
 |
| Job lineage showing specific filters applied to a Job |
Currently, the following input Record filters are supported:
- Filter by Record Validity
- Limit Number of Records
- Filter Duplicates
- Filter by Mapped Fields
Filter by Record Validity
Users can select if all, valid, or invalid Records will be included.
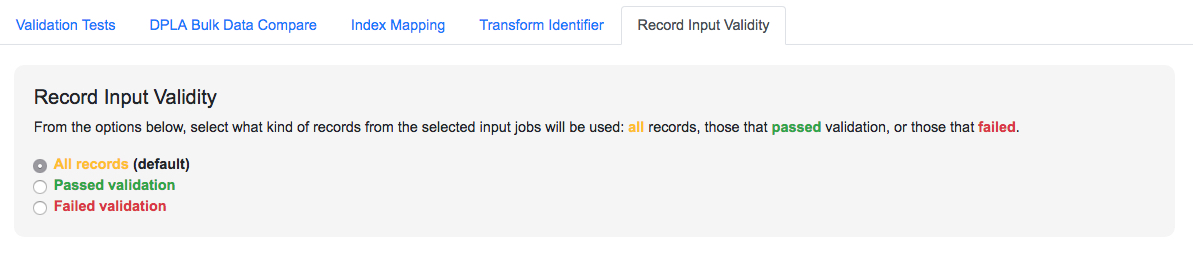 |
| Selecting Record Input Validity Valve for a Job |
Below is an example of how those valves can be applied and utilized with Merge Jobs to select only valid or invalid records:
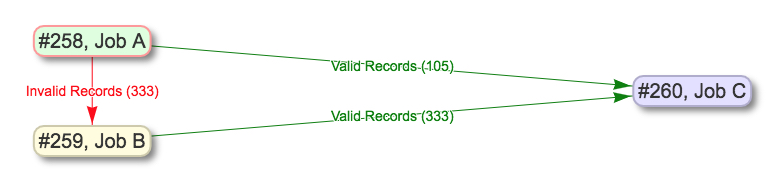 |
| Example of shunting Records based on validity and eventually merging all valid Records |
Keep in mind, if multiple Validation Scenarios were run for a particular Job, it only requires one Record failing one test, within one Validation Scenario, for the Job to be considered “invalid” as a whole.
Limit Number of Records
Arguably the simplest filter, users can provide a number to limit total number of Records that will be used as input. This numerical filter is applied after other filters have been applied, and the Records from each Input Job have been mixed. Given Input Jobs A, B, and C--each having 1,000 Records--and applying a numerical limit of 50, it’s quite possible that all 50 will come from Job A, and 0 from B and C.
This filter is best used for testing and sampling.
Filter Duplicates
This filter will remove duplicate Records based on matching record_id values. As these are used for publishing, this can be a way to ensure that Records are not published with duplicate record_id’s.
Filter by Mapped Fields
Users can provide an ElasticSearch DSL query, as JSON, to refine the records that will be used for this Job.
Take, for example, an input Job of 10,000 Records that has a field foo_bar, and 500 of those Records have the value ‘baz’ in that field. If the following query is entered, only the 500 Records with the value ‘baz’ will be used for the Job:
{
|
This ability offers the potential for taking the time to map fields in interesting and helpful ways, so that you can use those specially mapped fields to refine later Jobs. ElasticSearch queries can be quite powerul and complex, and in theory, this filter will support any query you apply.
Validation Tests
The most commonly applied optional parameters are Validation Scenarios. Validation Scenarios are pre-configured validations that will run for each Record in the Job. (See “Part 6: Configuration” for instructions on creating Scenarios.) Validation results are included when viewing a Job’s or Record’s details.
The Validation Test selection page looks like this for a Job, with checkboxes for each pre-configured Validation Scenario. A Validation Scenario might already be checked if it’s been marked to run by default:
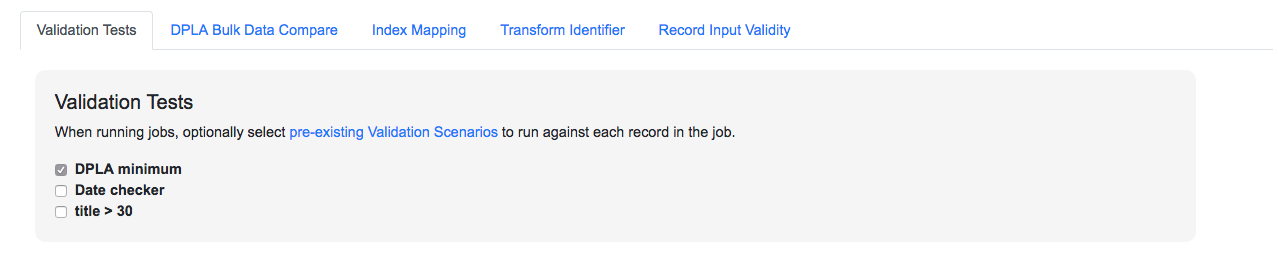 |
| Selecting Validation tests for a Job |
For more on Validation, see Part 11: Validation.
Transform Identifier
Note: While this feature is not deprecated outright in the current version, it hasn't been thoroughly tested in some time, so its status is uncertain. This section has been left largely untouched from the previous documentation, but any use of "Python code snippets" HAVE been deprecated.
When running a Job, users can optionally select a Record Identifier Transformation Scenario (RITS) that will modify the Record Identifier for each Record in the Job.
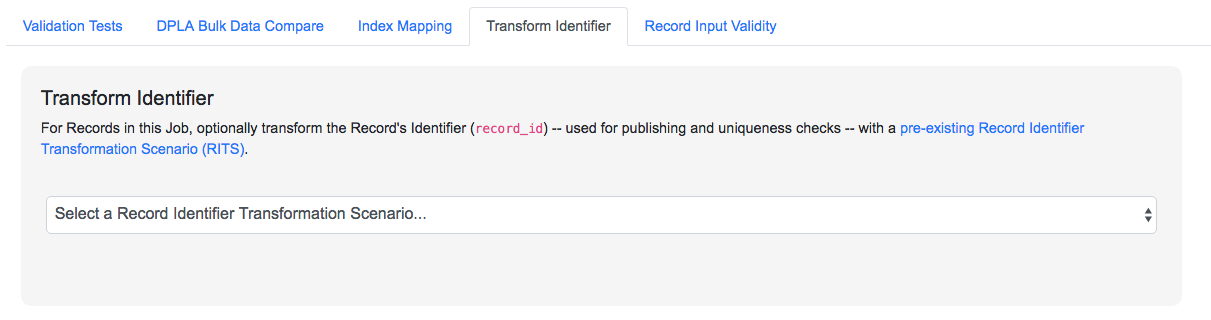 |
| Selecting a Record Identifier Transformation Scenario (RITS) for a Job |
Pipelines: “Upstream” and “Downstream” Jobs
As Combine runs more and more Jobs, certain Jobs will be related to either Jobs, either using the Records from a Job “upstream” to perform some other action on them, or providing Records for another Job “downstream” of it which will perform another action on those Records.
Take the Jobs below as an example:
 |
| Five connected Jobs |
In this example, Harvest Job A is the “root” or “origin” Job of this lineage. In Job A a set of Records were first harvested and created in Combine. All of the other Jobs in this lineage – B, C, D, and E – are “downstream” of Job A. From the point of view of A, there is a single pipeline. If a user were to reharvest A, potentially adding, removing, or modifying Records in that Job, this has implications for all other Jobs that either got Records from A, or got Records from Jobs that got Records from A, and so forth. In that sense, Jobs are “downstream” if changes to an “upstream” Job would potentially change their own Records.
Moving to B, only one Job is downstream, D. Looking at C, there are two Jobs that are downstream, Jobs, D and E. Moving to D, we can see that D actually has two Jobs that are upstream, Jobs B and C. This can be confirmed by looking at the “Input Jobs” tab for D:
 |
| Input Jobs for Job D, showing Jobs B and C |
If we look closely, though, we can see that no records are coming from Job C even though it’s listed as an Input Job for Job D. Why is this? The answer lies in the input filters applied to Jobs B and C: “De-Dupe Records” is true for both. We can infer then that Job B and Job C included Records that had the same record_ids, so once the Records from Job B were inputted into Job D, the duplicate records in Job C were all de-duped (i.e. skipped) during the Merge Job.
Here’s another way to look at the lineage from the perspective of Job D:
 |
| Alternate view of the lineage from the perspective of Job D |
So if we relate this back to the Job Management section, what would happen if we select Job A, click the “Re-Run Selected Jobs” button, and then slide “Include Downstream” to “on”? That would slate Jobs A-E to also re-run, one-by-one in a queue in order to ensure that each Job is getting updated Records from each Job that’s upstream of it:
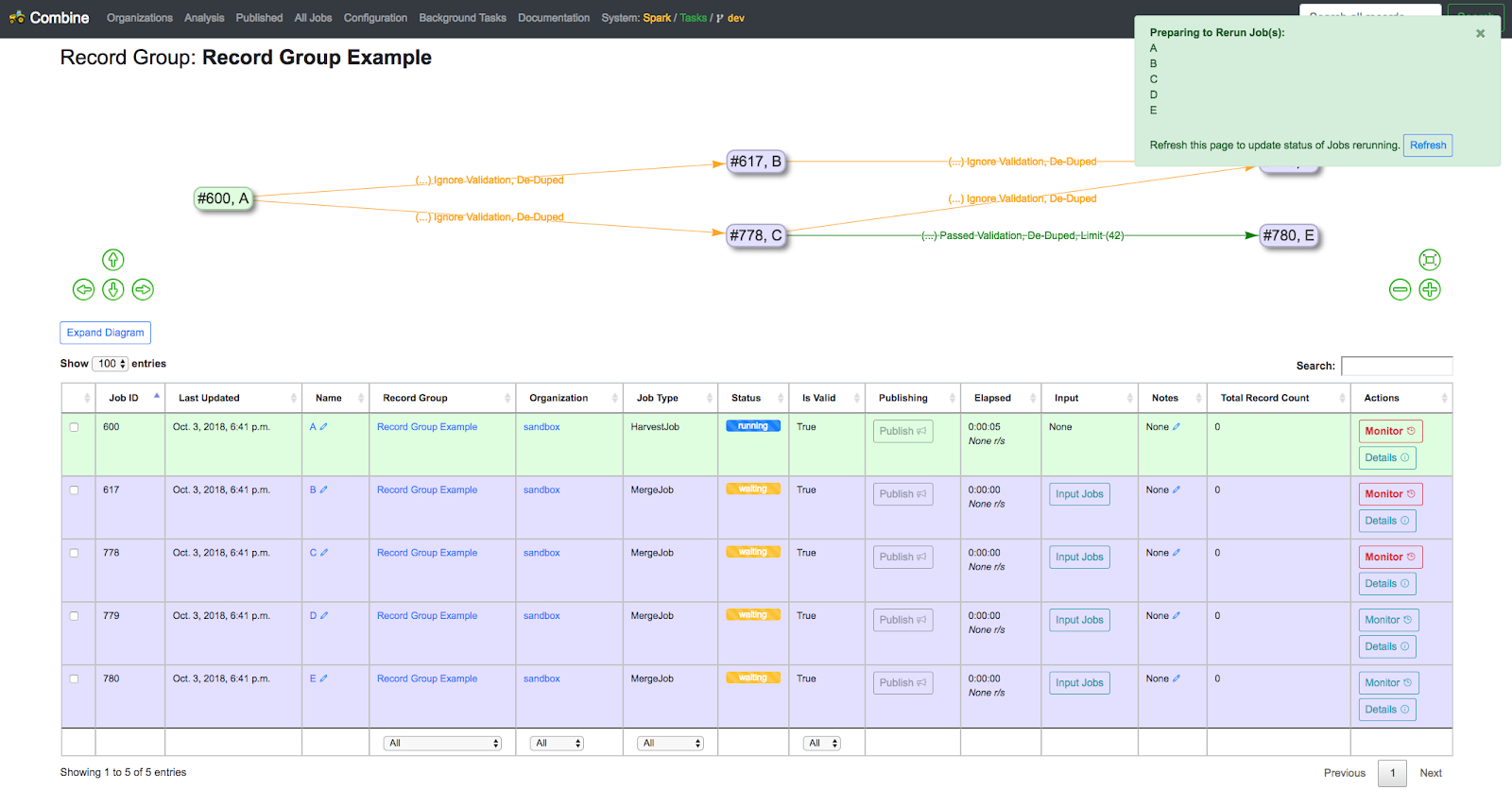 |
| Re-running Job A with the “Include Downstream?” slider moved to “on” |
As you can see–after the page is refreshed–the status for each Job has changed to “waiting,” and the Jobs will now re-run in order.
We also have the ability to clone Jobs, again with the option to include or ignore Jobs that are downstream. The following is an example of cloning C and not including downstream Jobs:
 |
| Cloning Job C and not including Jobs that are downstream of it |
All the validations, input filters, and parameters that were set for Job C are copied to the new Job C (CLONED), but because downstream Jobs were not included, Jobs D and E have not been cloned.
But if we clone Job C and do include downstream Jobs, then we see something like this:
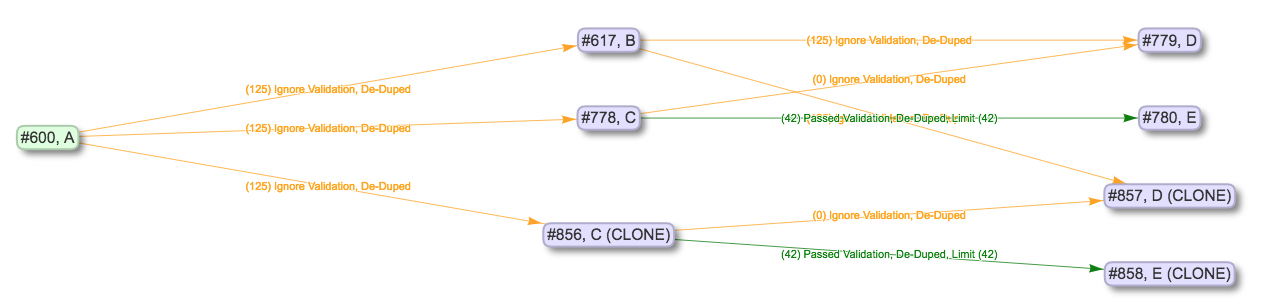 |
| Cloning Job C and including Jobs that are downstream of it |
Now there’s a line from Job B to the newly created cloned Job D (CLONE). Why has that happened? Because Job D was downstream from Job C during the clone–and, therefore, cloned as well–but it still required input from Job, which was not cloned. One can think of Job B as a set of Records that rarely change but are often required for other Jobs.
To get a sense about input Jobs for Jobs that are cloned, versus input Jobs for Jobs that are not cloned, we can look at this example. Job A is cloned and all of its downstream Jobs are included:
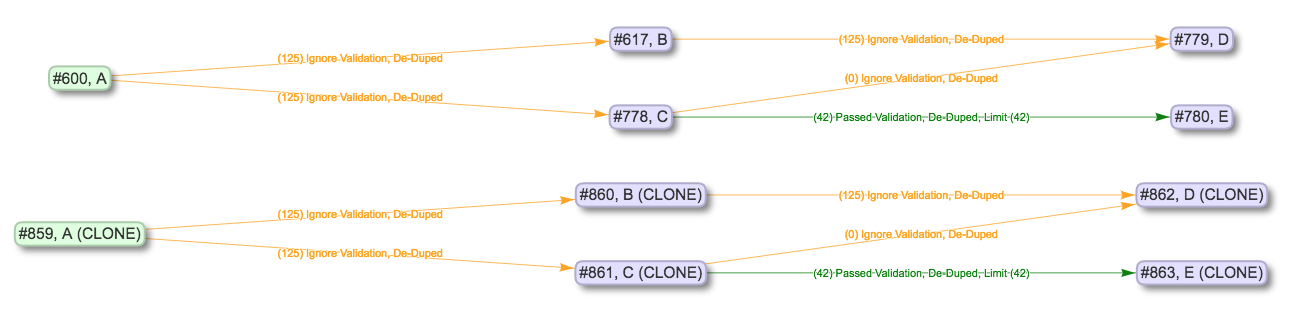 |
| Job A cloned with all downstream Jobs included |
In this pipeline, every other Job is downstream of Job A, so cloning Job A will also clone the entire pipeline and create a standalone copy of it. So you could clone an entire pipeline–and then re-run all of its Jobs in order to test them–without risking the integrity of the original pipeline before you know whether the re-run will be successful or not.
The same rules apply for other commands, such as deleting. In this example we are deleting Job A (CLONE) and including all downstream Jobs:
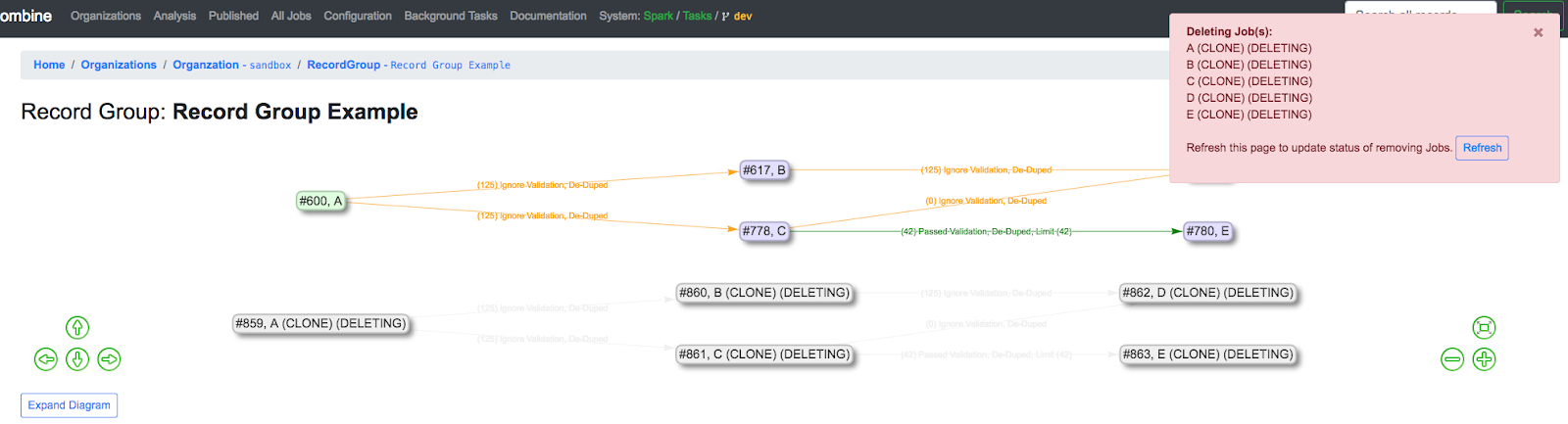 |
| Deleting Job A (CLONE) and all of its downstream Jobs |
“Pipelines” like these aren’t a formal structure in Combine, but they can be a very helpful way to think about a “lineage” of related Jobs. When paired with the granular control Combine gives you to set input filters for input Jobs, the ability to re-run or clone Jobs will allow you to set up complicated pipelines of related Jobs that you can re-use multiple times, as the next section will show.
Re-Running Jobs
In the previous section we examined “pipelines” of Jobs that flow from “upstream” to “downstream,” with one Job providing Records for the Job that follows it. In this section we look at how you can use the “re-run” command with a series of Jobs that really can make them resemble a “pipeline.” This method can be especially helpful when you expect to repeat a particular series of harvests, transformations, merges, validations, and other tasks many times in the future. The series can be preserved and then applied to new or updated Record Groups as they’re ingested into Combine over time.
When a Job is re-run, Combine takes the following actions first:
- all Records for that Job are dropped from the MongoDB
- all mapped fields in ElasticSearch are dropped (the ElasticSearch index)
- all validations and other information based on the existing Records are removed
However, what remains is important:
- the Job ID, name, notes
- all configurations, including:
- field mapping
- validations applied
- input filters
- etc.
- linkages to other Jobs; which Jobs were used as input (“upstream”), and which Jobs used this Job as input (“downstream”)
- the publish status of a Job, with corresponding publish_set_id (if a Job is published before re-running, the updated Records will automatically publish as well)
Consider the following example:
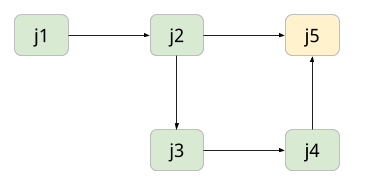 |
| An example of a lineage of Jobs |
Records from an OAI Harvest Job, J1, are used as input for Job J2. A subset of these are passed to Job J3, perhaps because they failed a particular Validation. These are then fixed and successfully Validated in Job J4. Then the Validated Records from Job J2 and Job J4 are finally merged in Job J5, creating a final form for all of the Records. Each step can apply a different set of Validations and mappings to fix various errors and keep the Records moving along.
Now, let’s assume several months pass, and Record Groups harvested the first time have had new Records added and the metadata of some older Records revised or corrected. To add these changes to Combine we’ll need to re-run the first, harvest, Job J1, again. If the “re-run” option didn’t exist, we would have to recreate the entire series of Jobs that we used before, step-by-step. The result would be an entirely new set of Records that–because of the changes during the intervening months–would almost, but not quite, match the original set of Records. In some cases, having both of these sets might be desirable, but not always.
Instead, if we re-run Job J1, all of the Jobs downstream of Job J1 will also automatically re-run, all the way to Job J5.
Here’s how this example would look in Combine:
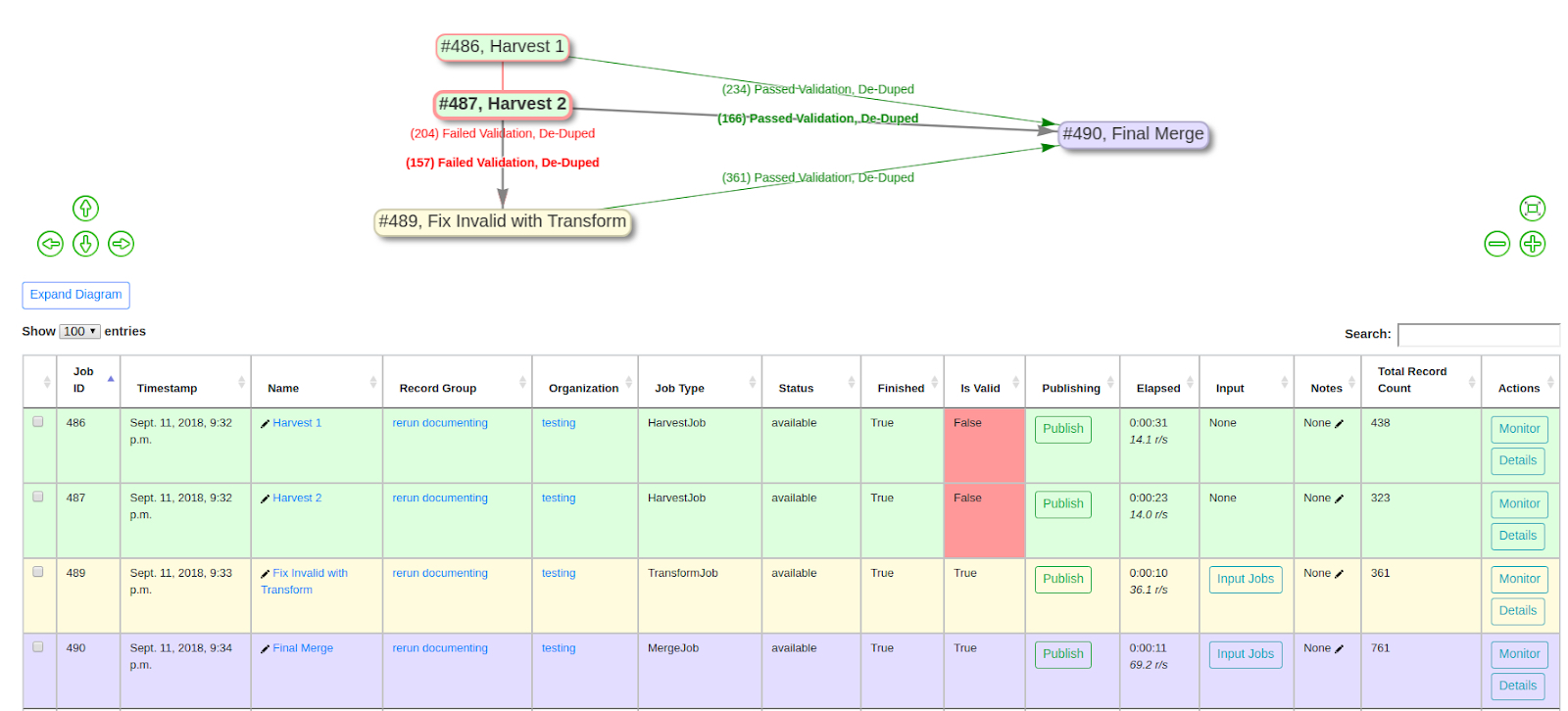 |
| A re-run of a “Pipeline” |
In this pipeline:
- first, there are two harvests (the green rows)
- next, all invalid Records are sent to a Transformation Job that fixes their Validation problems (the yellow row)
- then all the valid Records from that Transformation Job, and the original Harvests, are merged together in a final Job (the purple row)
The details of these hops are hidden from this image, but there are validations, field mappings, and other configurations at play here. If a re-harvest is needed for one, or both, of the harvest Jobs, re-running them will trigger all of their “downstream” Jobs, refreshing the Records along the way.
Next: Harvesting Records